Graphs: The Driving Force Behind Git Commits
Understanding the underlying data structure of your git commit history

I'm a software engineer by profession & a technical writer by passion. I've written blogs, tutorials, and guides for Memphis, Paessler PRTG, AI Superior, Massdriver, and more. Open for gigs (email: nimra1408@gmail.com)
I love Node.js & enjoy API documentation.
While reading about how Git commit works, I came across this definition (source: Educative):
Git keeps track of your project through a series, or chain, of commits. The most recent snapshot of your repository is referred to as the HEAD.
As soon as you create a new commit, it will directly link to the HEAD. However, since the latest commit is now the most recent one, it will be considered the HEAD instead, replacing the previous one.
And that got me thinking: does git use linked list at its core? I mean, if you think about it, every time you create a new commit, a node is created, and it's linked to the HEAD. And it turns out, I was thinking in the right direction - Git uses something called DAG or directed acyclic graph, which can be best visualized as a linked list of commits.
But to really understand how Git uses these graphs, there's a lot that must be unpacked first.
First things first: What is a DAG?
DAG or directed acyclic graph is quite easy to understand if we look at the three words individually. Let's start with graph - this refers to your regular graph with nodes and edges. Here's a basic sample:
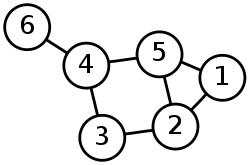
Directed means that each node in the graph follows a specific direction. In other words, it goes from one node to another in a certain direction, with this direction representing the relationship between nodes, like this:
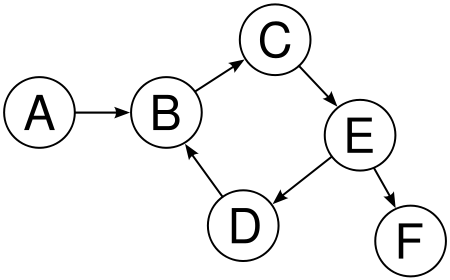
Finally, acyclic means there are no cycles in the graph. You can't start a node and follow the directed edges to ever return to the same node by traversing the graph. As a result, there are no loops in the graph. So if we put it all together, this is what a DAG looks like:
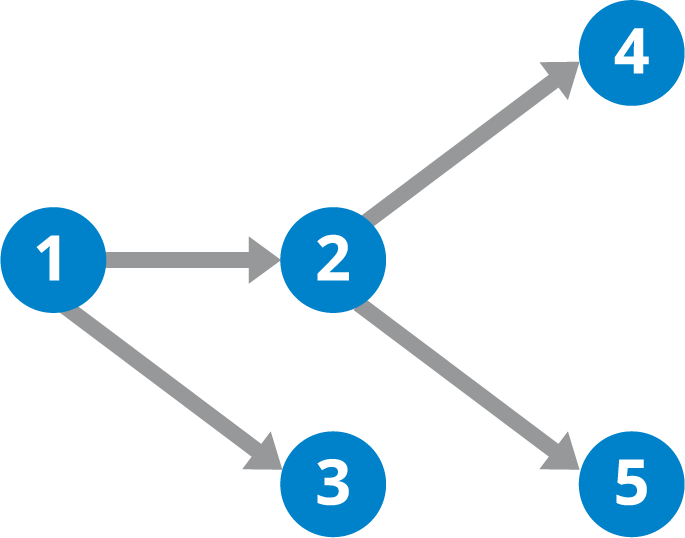
Where does DAG fit in Git?
Your commit history can be best represented as a DAG. Each commit is a node in the graph, and the directed edges represent the relationships between commits. A commit points to its parent commit, indicating the commit that came before it in the history.
Two git commands are important to discuss here: git add & git commit.
Git Add
When you run git add, you basically tell git to prepare the changes in the working directory to be committed. To do so, git uses two things: index and blob objects.
The index or the staging area is considered the starting point of the changes you wish to commit, and represents the state of your files at a particular point in time. Think of it as the intermediary between your current working directory and the repository that contains references to the corresponding blob objects representing the file contents. The index is not a commit itself, but just a staging area for your next commit.
Blob objects store the content of individual files in the repository. When you run git add, Git creates or updates the corresponding blob object for that file. It computes the hash (SHA-1) of the file's content, and if it's a new file or if the content has changed, it creates a new blob object. The blob object is then associated with the file's path and stored in the Git object database.
Here's a simple visualization:

The changes are now ready to be committed in the next step.
Git commit
When you run git commit, a new commit object is created depending on the changes staged in the index. To do so, git uses three things: commit objects, tree objects, and parent commits.
A commit object represents a snapshot of the entire repository at a given point in time. When you run git commit, Git creates a new commit object that includes metadata such as the author, committer, timestamp, and commit message. The commit object also references the top-level tree object that represents the state of the repository's directory structure at that commit.
The tree object represents the state of the repository's directory structure. It contains references to blob objects that store the content of individual files, as well as references to other tree objects for subdirectories. The tree object associated with the new commit is created based on the contents of the index. Git constructs the tree object by traversing the index and creating tree entries for each file or directory.
The new commit object includes a reference to its parent commit, representing the commit that came before it in the commit history, which helps to establish the link between the new commit and the previous commit. This link forms a chain of commits, essentially creating a linked list of commits in the DAG. The latest commit becomes the new head of the branch, and the branch reference is updated to point to the new commit, adding it to the commit history.
Here's a simple visualization:


And that's really all there is to it. To sum up, git commit uses directed acyclic graphs to keep track of your commit history. Git add and git commit are two of the most important commands that any software developer must know, and it doesn't hurt to know how things work under the hood. Hopefully, you now have a better understanding of what goes in when you commit your code




